There’s a whole paper by Hadley Wickham about tidy data but it’s in a PDF so you’re probably not going to read it. Here’s the paper’s definition of tidy data:
Each variable forms a column.
Each observation forms a row.
Each type of observational unit forms a table.
As Dr Wickham notes, this is Codd’s 3rd Normal Form but in statspeak rather than databasespeak.
The meaning of “variable” and “observation” depend on what we’re studying, so tidy data is a concept that you mostly learn through experience and ✨vibes✨.
Now we’ll explore what tidy data looks like for an NBA results dataset.
4.1 Get the data
from pathlib import Pathimport polars as plimport pandas as pdpl.Config.set_tbl_rows(5)pd.options.display.max_rows =5nba_dir = Path("../data/nba/")column_names = {"Date": "date","Visitor/Neutral": "away_team","PTS": "away_points","Home/Neutral": "home_team","PTS.1": "home_points",}ifnot nba_dir.exists(): nba_dir.mkdir()for month in ("october","november","december","january","february","march","april","may","june", ):# In practice we would do more data cleaning here, and save to parquet not CSV.# But we save messy data here so we can clean it later for pedagogical purposes. url =f"http://www.basketball-reference.com/leagues/NBA_2016_games-{month}.html" tables = pd.read_html(url) raw = ( pl.from_pandas(tables[0].query("Date != 'Playoffs'")) .rename(column_names) .select(column_names.values()) ) raw.write_csv(nba_dir /f"{month}.csv")nba_glob = nba_dir /"*.csv"pl.scan_csv(nba_glob).head().collect()
Polars does have a drop_nulls method but the only parameter it takes is subset, which — like in Pandas — lets you consider null values just for a subset of the columns. Pandas additionally lets you specify how="all" to drop a row only if every value is null, but Polars drop_nulls has no such parameter and will drop the row if any values are null. If you only want to drop when all values are null, the docs recommend .filter(~pl.all_horizontal(pl.all().is_null())).
Note
A previous version of the Polars example used pl.fold, which is for fast horizontal operations. It doesn’t come up anywhere else in this book, so consider this your warning that it exists.
4.3 Pivot and Melt
I recently came across someone who was doing advanced quantitative research in Python but had never heard of the Pandas .pivot method. I shudder to imagine the code he must have written in the absence of this knowledge, so here’s a simple explanation of pivoting and melting, lest anyone else suffer in ignorance. If you already know what pivot and melt are, feel free to scroll past this bit.
4.3.1 Pivot
Suppose you have a dataframe that looks like this:
As you can see, .pivot creates a dataframe where the columns are the unique labels from one column (“ticker”), alongside the index column (“date”). The values for the non-index columns are taken from the corresponding rows of the values column (“price”).
If our dataframe had multiple prices for the same ticker on the same date, we would use the aggregate_fn parameter of the .pivot method, e.g.: prices.pivot(..., aggregate_fn="mean"). Pivoting with an aggregate function gives us similar behaviour to what Excel calls “pivot tables”.
4.3.2 Melt / Unpivot
Melt is the inverse of pivot. While pivot takes us from long data to wide data, melt goes from wide to long. Note: Polars has recently replaced its melt method with an unpivot method.
If we call .unpivot(index="date", value_name="price") on our pivoted dataframe we get our original dataframe back:
Code
pivoted.unpivot(index="date", value_name="price")
shape: (12, 3)
date
variable
price
date
str
i64
2020-01-01
"AAPL"
100
2020-01-02
"AAPL"
110
2020-01-03
"AAPL"
105
…
…
…
2020-01-02
"NFLX"
420
2020-01-03
"NFLX"
440
4.4 Tidy NBA data
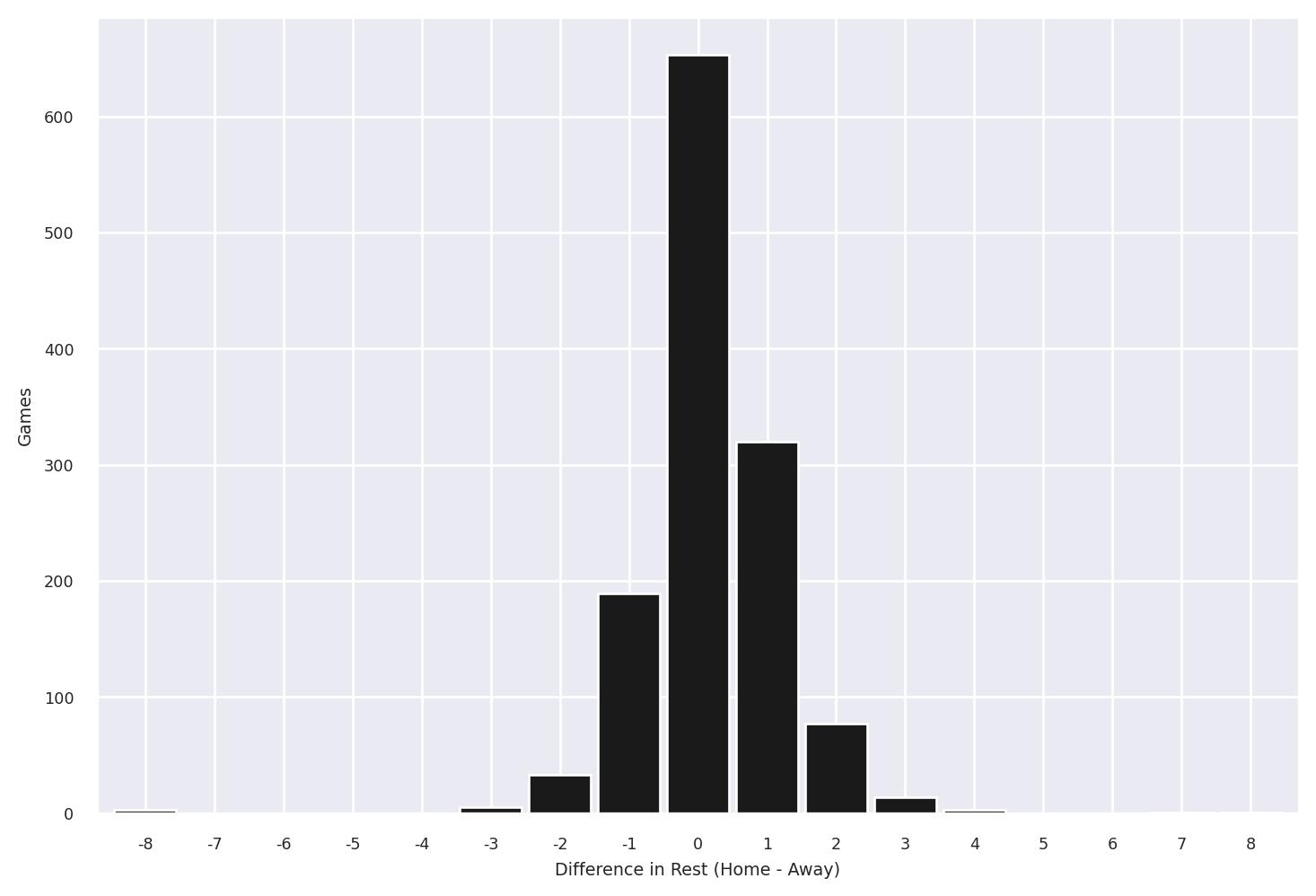
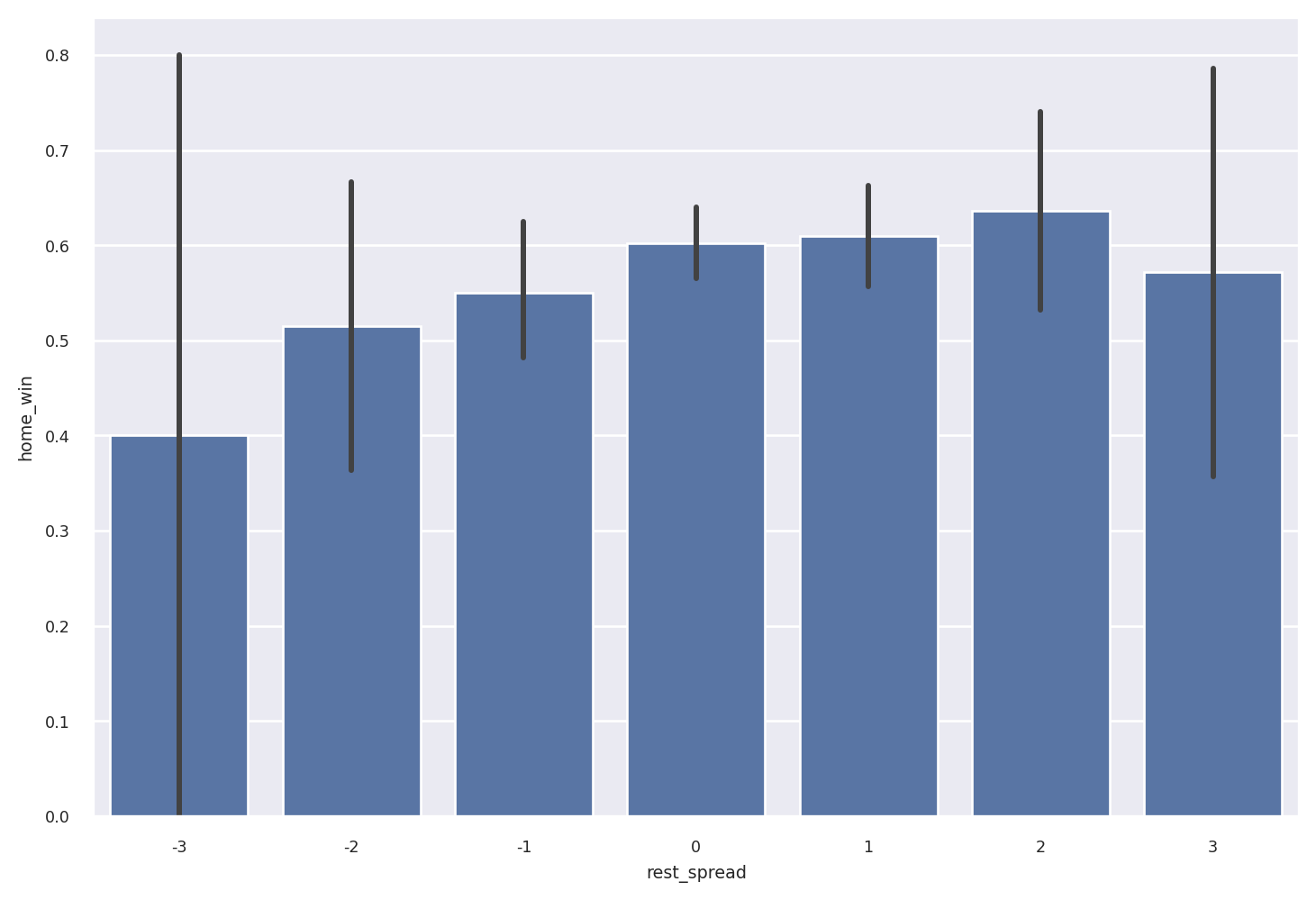
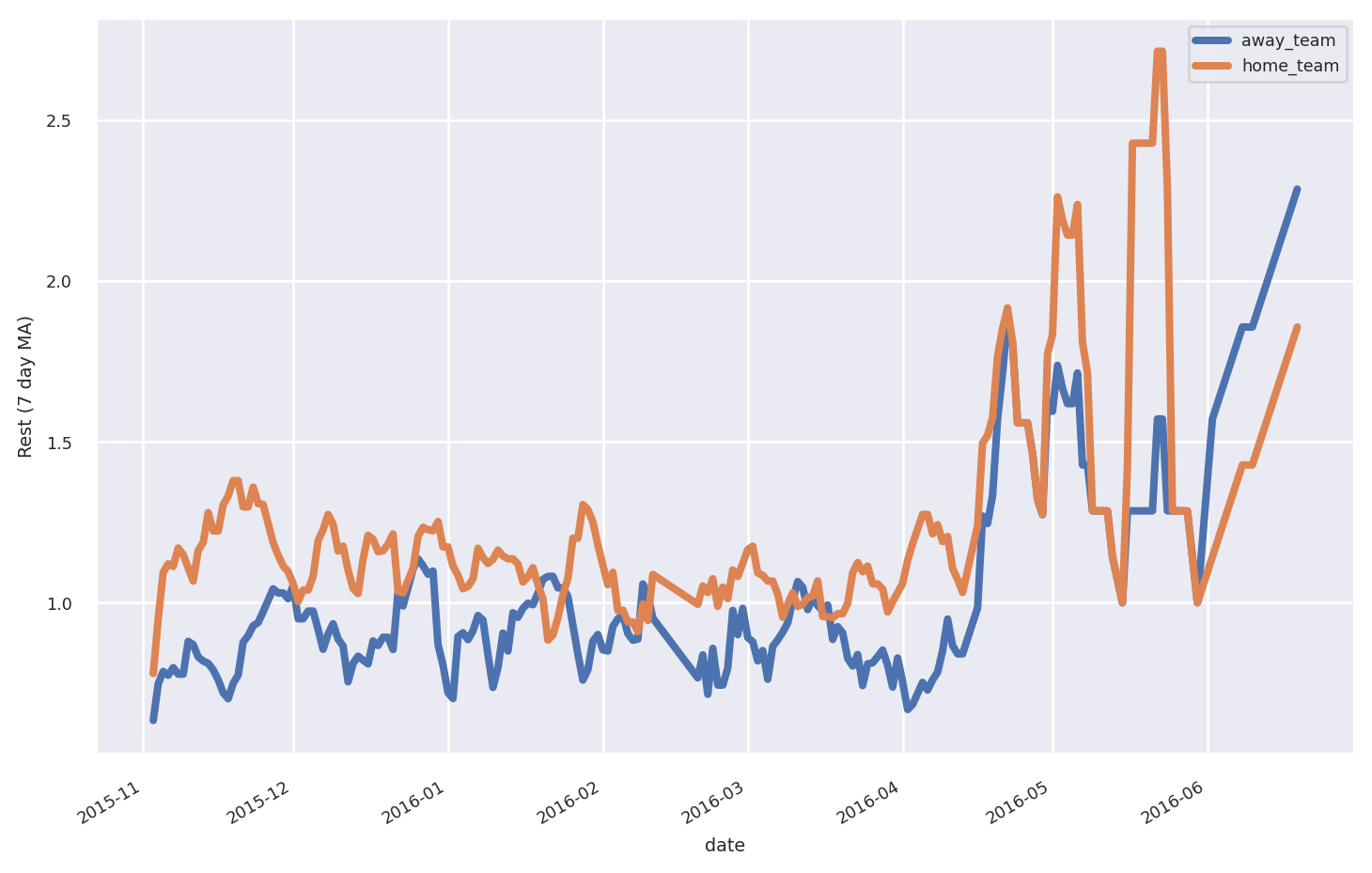
Suppose we want to calculate the days of rest each team had before each game. In the current structure this is difficult because we need to track both the home_team and away_team columns. We’ll use .unpivot so that there’s a single team column. This makes it easier to add a rest column with the per-team rest days between games.
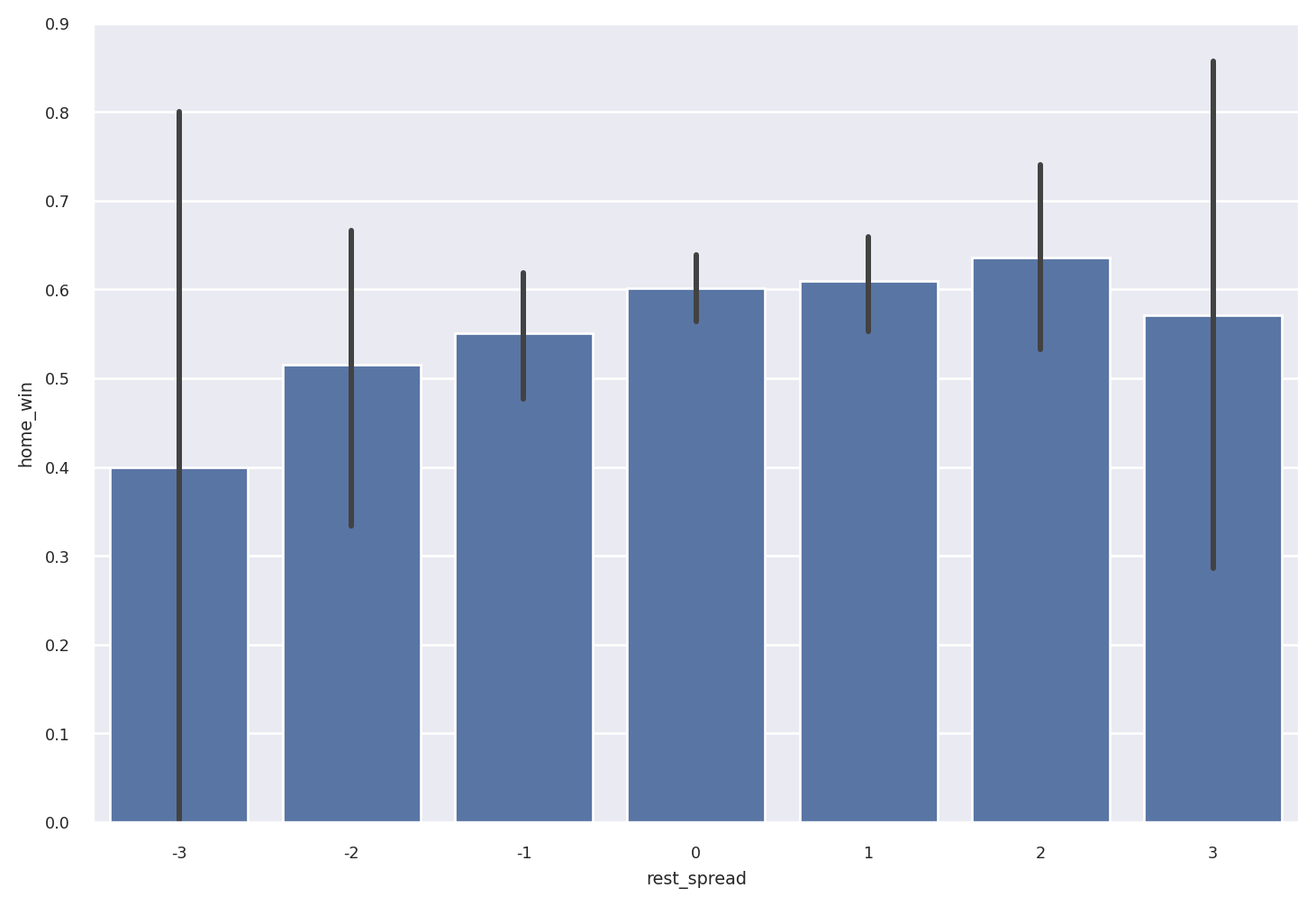
Now we use .pivot so that this days-of-rest data can be added back to the original dataframe. We’ll also add columns for the spread between the home team’s rest and away team’s rest, and a flag for whether the home team won.
One somewhat subtle point: an “observation” depends on the question being asked. So really, we have two tidy datasets, tidy for answering team-level questions, and joined for answering game-level questions.
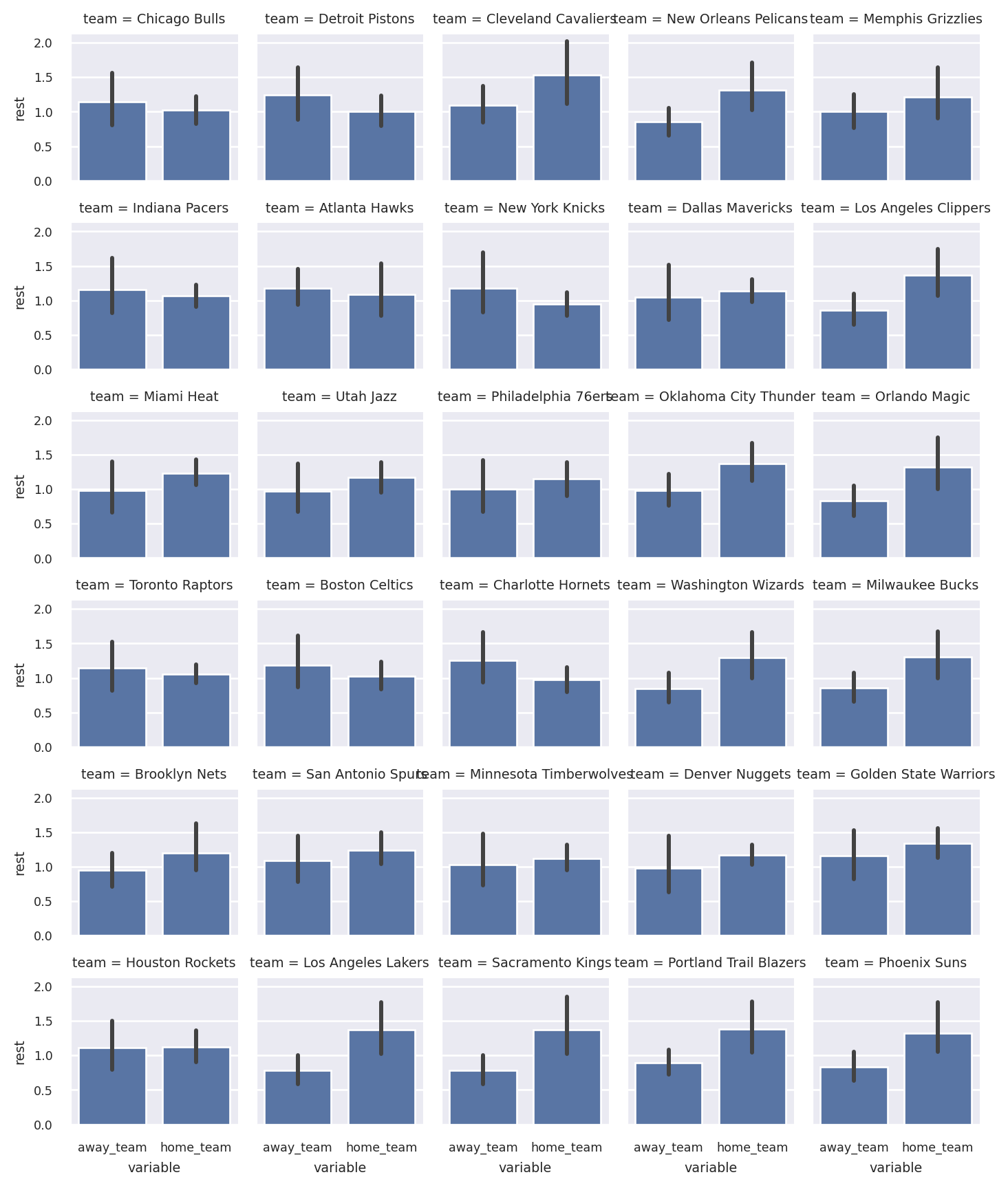
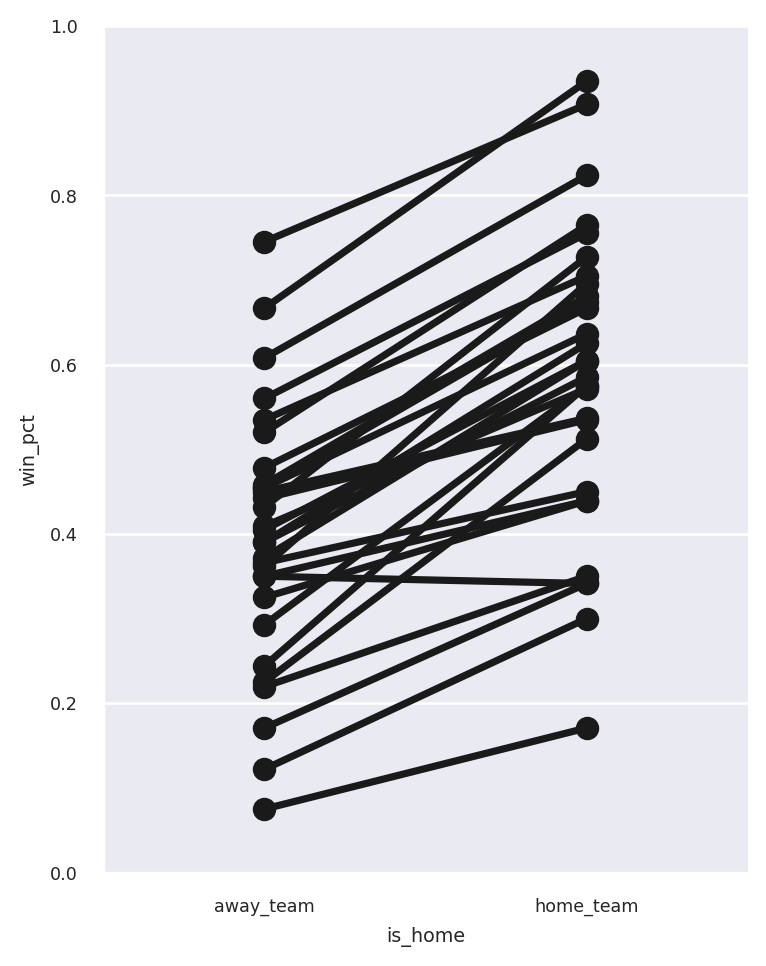
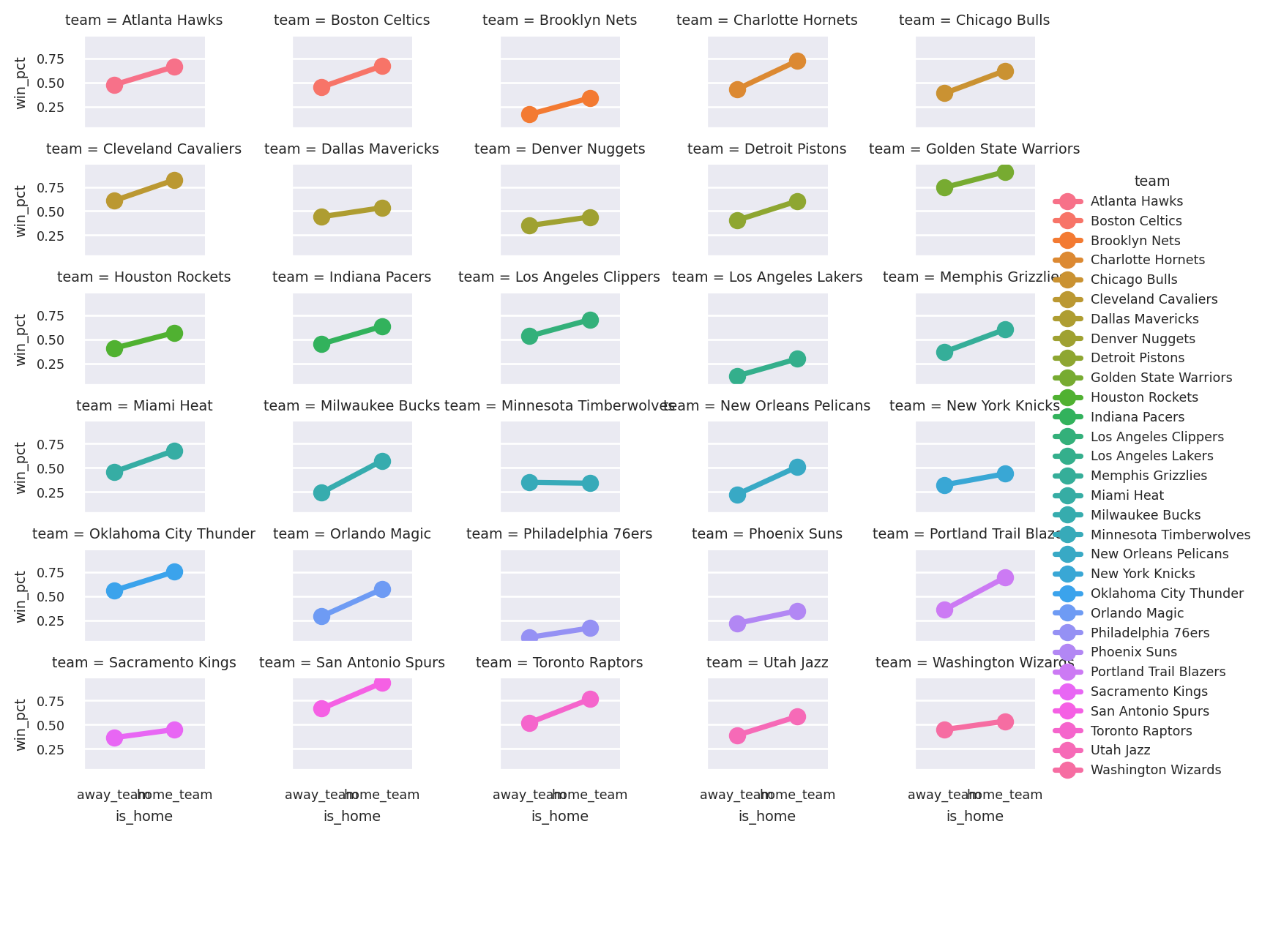
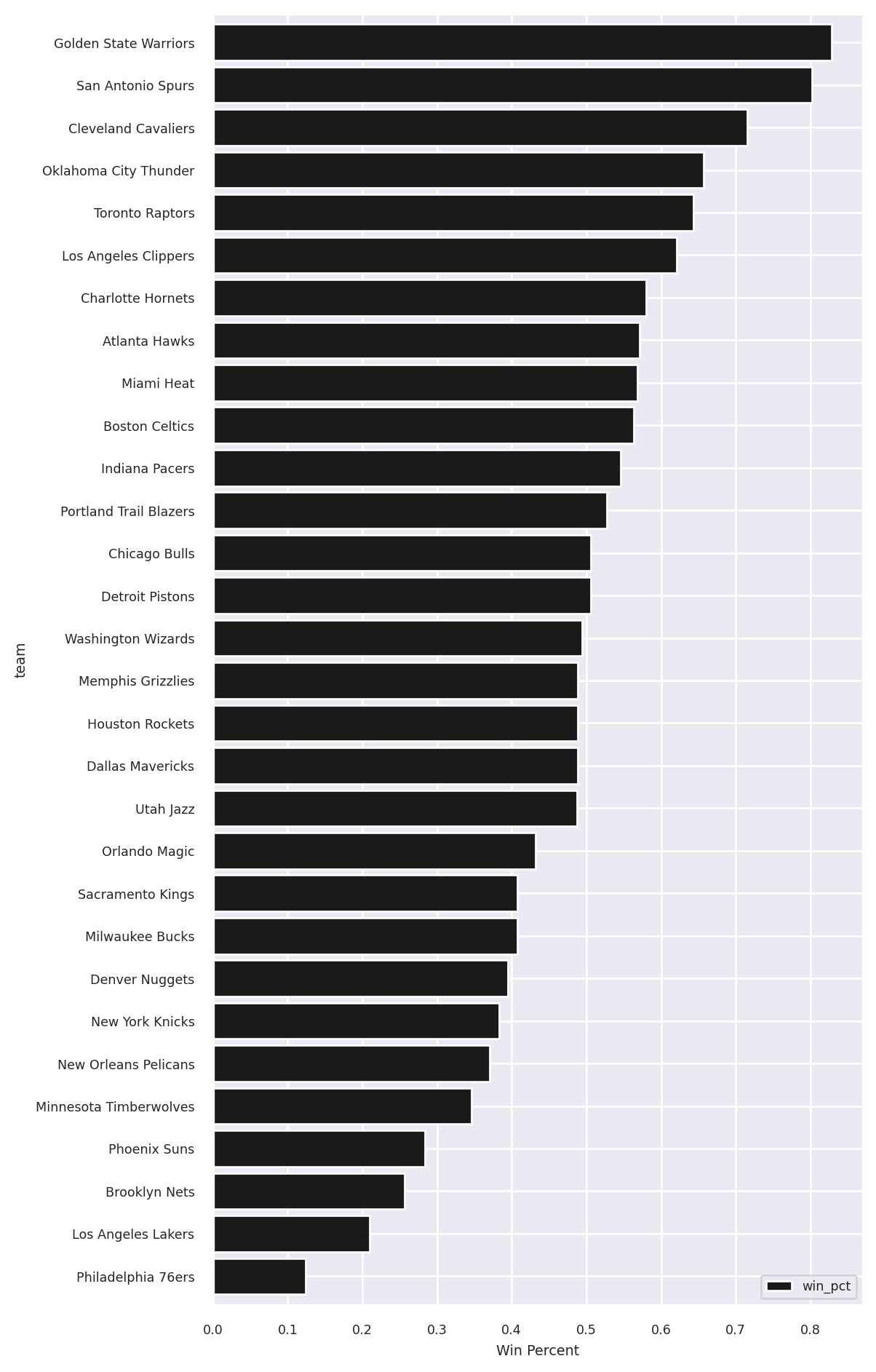
Let’s use the team-level dataframe to see each team’s average days of rest, both at home and away:
Pandas has special methods stack and unstack for reshaping data with a MultiIndex. Polars doesn’t have an index, so anywhere you see stack / unstack in Pandas, the equivalent Polars code will use melt / pivot.